Detection Chokepoints: Starting from Scratch
If you do detection work long enough, you start to notice the same pattern. A new loader
shows up, RMMs are now the new C2, AiTM kits keep evolving, and each one gets its own
detection. You write it, test it, send it into production and move onto the next threat. The problem is what most of
those detections are pinned to (a file name, a hash, specific tool artifacts etc.) is the part the attacker
fully controls. They can recompile, rename, or swap the whole framework to evade detection. Pin your rule
to mimikatz.exe and you’ve signed up to lose the moment someone changes a filename.
TL;DR for busy defenders
- Pin detections to the action a threat actor has to perform, not the filename, hash, or tool they control. Credential dumping still has to reach credential material even when Mimikatz disappears.
- Start with the Research-tier rule to learn what normal looks like in your environment. Refine it into a Hunt rule, then promote it to an Analyst alert once the false positives are understood.
- Use Attack Chains to find where unrelated threats converge. Use Trends to see which variations around those fixed points need tuning.
- ClickFix is the working example: clipboard write → user execution → network activity. Cover more than one stage, pair the detection with prevention, and watch it fire in a lab before shipping it.
A better way to think about it is to flip the question. Instead of asking what the attacker is using, ask what part of this they can’t change.

WTF is a chokepoint?!
The term comes from military strategy. You force an opponent into a narrow passage they have to move through to reach their objective, and that bottleneck is where you hold the advantage: they have traverse the chokepoint in a specific manner. This isn’t a new idea in detection engineering, either. The chokepoint language I use comes straight out of Matt Graeber’s threat research at Red Canary and Joshua Prager from SpectreOps. Both research methodoligiesa (work through what has to be true for it to succeed, then find the step the attacker can’t control) resonated with me, and it’s genuinely how I think about threats now. That step they can’t control is the chokepoint, and it’s where durable detection lives.
Take credential theft from LSASS. There are a lot of tools that do it (Mimikatz, comsvcs.dll,
ProcDump, Nanodump, the credential-dumping built-ins in just about every C2 framework) and they
all use different code, different syscalls, and different tricks to stay quiet. But every one of
them has to do the same thing:
Open a handle to
lsass.exeand read its memory to get at the credential material.
The kernel mediates that handle. You can’t read the memory without it. The tooling has rotated for over a decade (the LOLBin era, direct syscalls, handle duplication, BYOVD PPL bypasses) and that one step never moved. It can’t, because it’s the mechanism of the technique. That’s the chokepoint.
Detection is a Game of Economics
Anchoring to an invariant isn’t only about durability: it’s about who pays. A detection pinned to a tool is a free reset for the attacker: rename it, recompile it, swap the whole framework, and your rule is dead at no cost to them. A detection pinned to the step they can’t skip makes every evasion attempt cost real engineering time. Time is money on both sides of this, and the whole game is to spend theirs instead of yours.
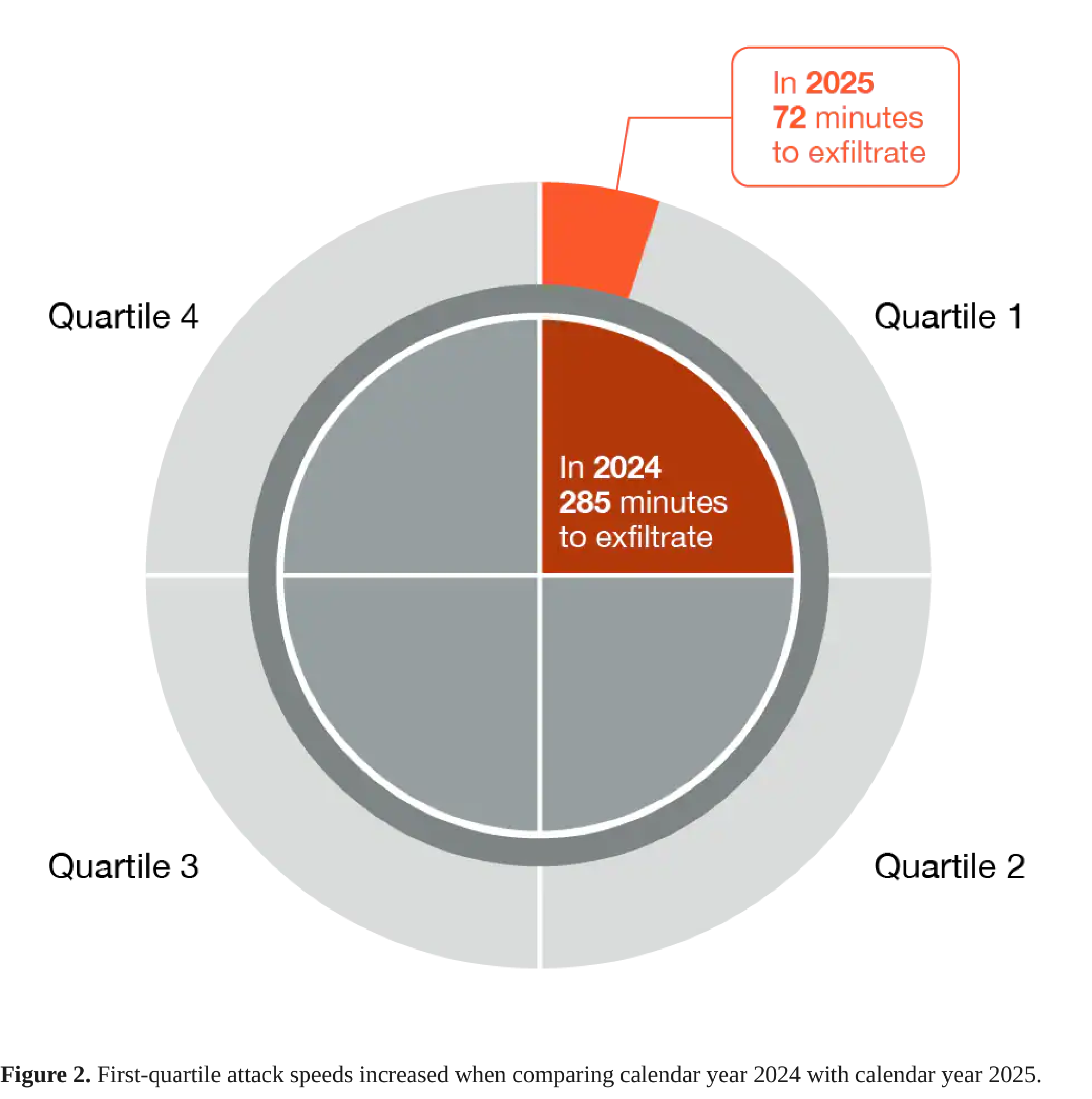
The speed to develop more tradecraft at a higher velocity increases each year, even more so now with the wide adoption of LLMs. The 2020 ransomware chain was a manual, roughly 10–14-day affair: break in, run discovery, dump credentials, escalate, move laterally, then deploy. The 2025 version is broker-enabled and squeezed to under 48 hours, with whole phases (discovery, recon, often privilege escalation) skipped because someone else already did them. Mandiant’s M-Trends 2025 shows the same thing in aggregate: median dwell time has fallen year over year. Palo Alto’s 2026 Unit 42 Global Incident Response Report puts a number on the sharp end of that curve: the fastest quartile of intrusions went from initial compromise to data theft in 285 minutes in 2024, and just 72 minutes in 2025. You have a shorter window to catch an intrusion, so the detection needs to be located where a threat actor needs to make contact with the environment in order to progress to their objective.
Infostealer logs are now a routine first step into a network (HudsonRock, Red Canary), and Initial Access Brokers sell that foothold pre-enriched: privilege level, access type, even which EDR is running in the environment (Cyberint). The tooling layered on top rotates constantly precisely because it’s cheap and interchangeable, which is the exact reason a detection pinned to it keeps dying.
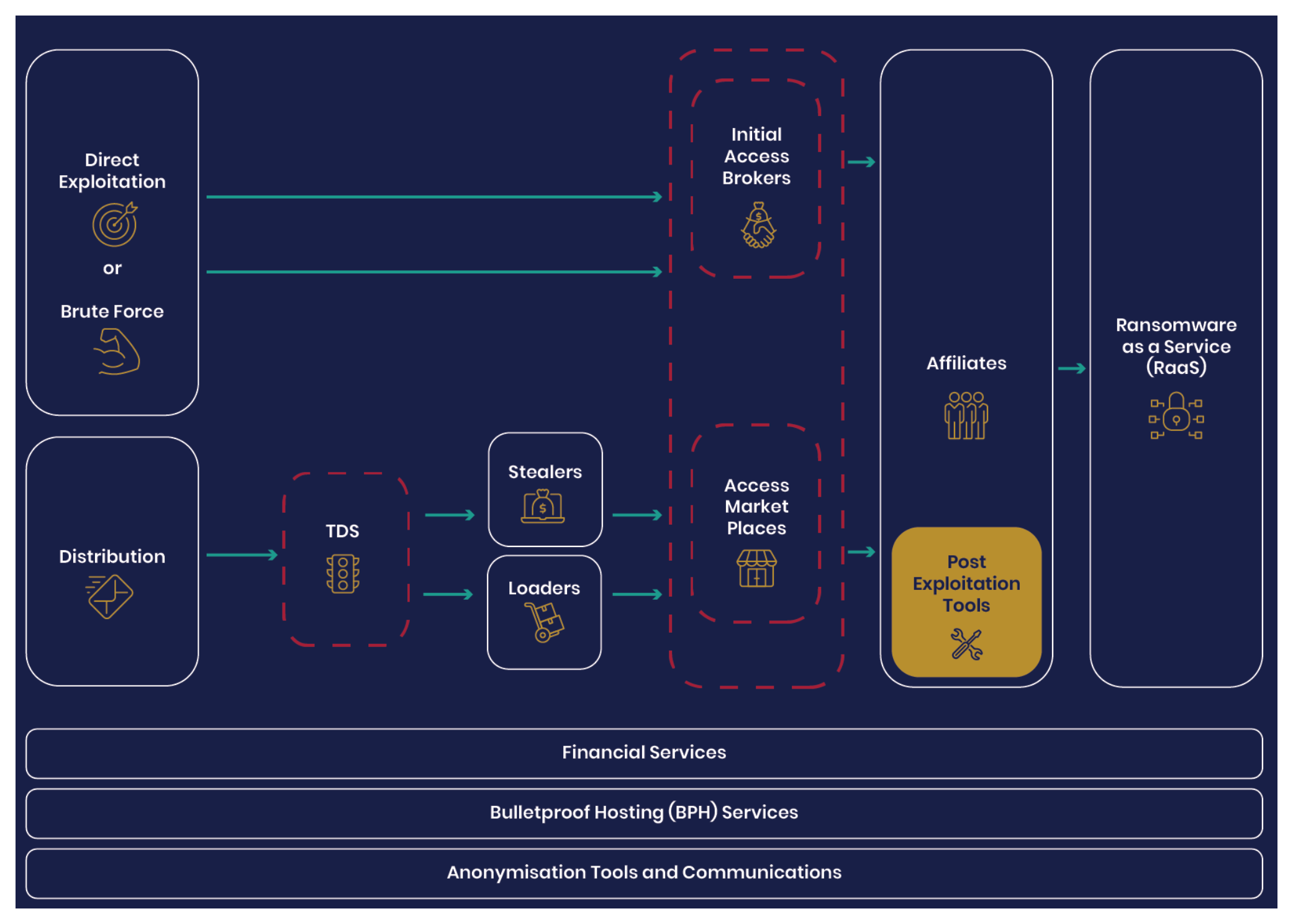
The RaaS ecosystem has commoditized the entire Ransomware operation pipeline. The UK’s NCSC and NCA mapped the supply chain: every function below can be run by a different actor and sold to the others as a service. Specialization is exactly why the end-to-end attack got fast, and it’s also why the tooling at any single stage is so disposable.
When focusing on chokepoints, unrelated threats naturally overlap on the same invariant steps. One detection placed there covers many actors at once, and one log source ends up catching many techniques: you pay the engineering cost once, on the part that can’t change, instead of re-paying it for every renamed tool. And because you’re reasoning about what has to be true for the technique to work, you can usually see the next variation coming before it even has a name.
That’s the bet the whole project makes: when the tooling rotates and the TTPs evolve, the chokepoint remains.
Cataloguing Chokepoints
Detection Chokepoints is a free, open knowledge base built around that one question, applied across techniques. Right now there are 13 chokepoint entries spanning six ATT&CK tactics (initial access, execution, defense evasion, credential access, lateral movement, and persistence) with more on the way.
Each entry isn’t a single rule. It breaks the technique down to its invariant, the observable that exposes it, the log sources that cover it, and the actual detection logic. And the rules come at three maturity tiers, because where you deploy a detection matters as much as whether it’s correct:
| Tier | What it’s for |
|---|---|
 Research Research |
Broad baseline, high noise: for establishing visibility, not for alerting |
 Hunt Hunt |
Behavioral context, moderate noise: for periodic sweeps and analyst triage |
 Analyst Analyst |
Production-ready, low noise: for the alert that pages someone |
The tiers exist because the most common way a good detection idea dies is someone dropping the high-fidelity rule straight into an environment that was never baselined, drowning in false positives, and ripping it out. Start at Research, learn what normal looks like in your environment, then refine as needed.

Beyond the chokepoint entries, Attack Chains look at where unrelated actors converge on the same kill-chain stage: when several groups all route through the same step, that overlap is your priority, because the adversaries effectively voted on it for you.
Trends

Chokepoints tell you what a threat actor can’t change or is expensive to change; Trends tell you what’s moving. This section is data-driven analysis of how the landscape is shifting (which delivery families are accelerating, which evasions are showing up, which variant is about to become the dominant one) so you can tune the Hunt-tier rule before the wave instead of after the incident.
The methodology that ties all of it together lives in the Framework section: every technique gets worked through the same three questions: what’s its scope (one technique, or a chain of them?), what variations exist or could plausibly exist, and what prerequisites have to be true for it to work at all. That last question is where the chokepoint falls out: the prerequisite that can’t be designed away. We’ll dive deeper into Attack Chains and Trends in a future post.
Case Study: ClickFix
The idea crystallized for me with ClickFix. The ClickFix threat has dominated headlines for the past few years
Huntress, and the variants just
kept coming: FileFix, TerminalFix, DownloadFix, each with a different lure. If you only pay attention to the variations,
you’ll be chasing them forever. But step back and they all funnel through the same place: a user
is talked into running a command, a scripting interpreter executes it under explorer.exe or a
browser process, and a second stage comes down from the network. Detect that shape and you catch the
variants that haven’t been named yet. If you want to see what that looks like as an actual entry
(the staged detections, the Sigma rules, the emulation script) I walked through the ClickFix one
here.
Where to Start
None of this replaces keeping up with tooling. But if you’re underwater and don’t know where to begin, start with what the attacker can’t avoid. Pick a chokepoint, deploy the Research-tier rule, watch it for a week to learn your noise, and climb the tiers from there. When the tool rotates next month, your detection is still sitting on the part that can’t change.
If you’ve reverse-engineered a technique down to its invariant, please contribute! Detection Chokepoints.